手搓神经网络系列之 —— 梯度反传函数具体怎么写?(二)
上篇文章的文末对广播机制对梯度反向传播的影响做了点讨论,但在张量运算方面仍留了两个坑,本文将努力填掉第一个坑:张量乘法。
本系列全部代码见下面仓库:

如有算法或实现方式上的问题,请各位大佬轻喷 + 指正!
注意,这里的乘法不再是 element-wise Product 了,而是 “货真价实” 的 Tensor Multiplication。前文提到过,张量乘法分为以下三种:
- 一维向量间点乘 ——Dot
- 多维张量与一维向量相乘 ——Mv
- 多维张量与多维张量相乘 ——Mm
如此从维数上进行区分是为了方便在反向传播时不容易乱套。
下面先给出正向传播的代码,正向传播非常的无脑:
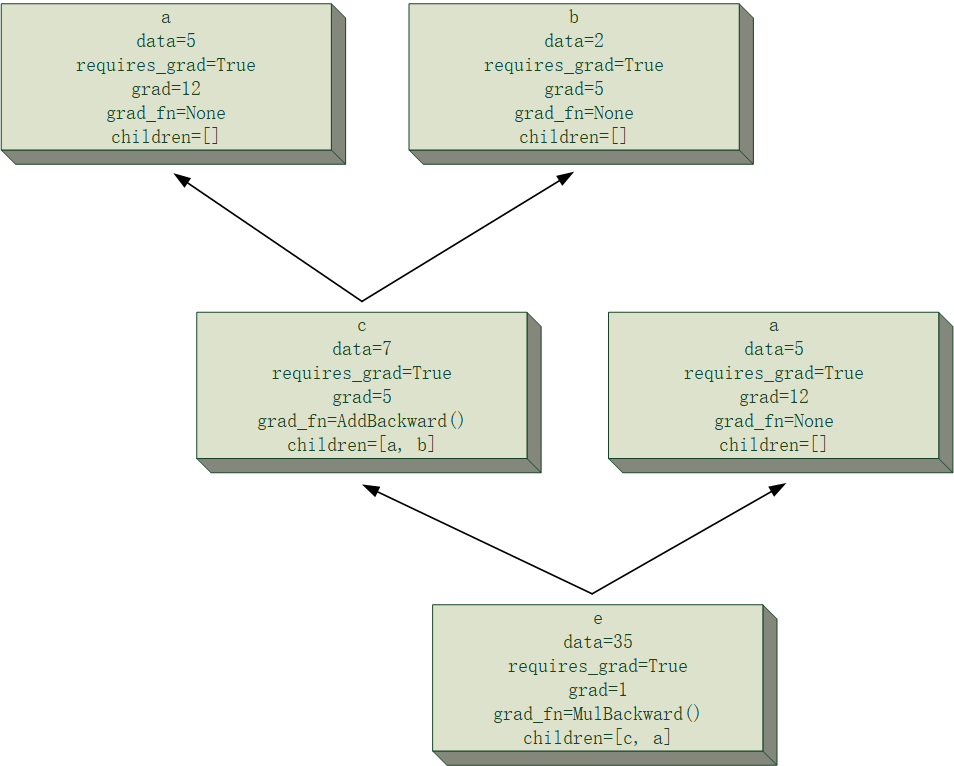
def __matmul__(self, other):
assert isinstance(other, Tensor), f"argument 'other' must be Tensor, not {type(other)}"
result = Tensor(self.data @ other.data, requires_grad=self.requires_grad or other.requires_grad)
if not result.grad_enable:
return result
result.children = [(self, None), (other, None)]
if self.ndim == 1 and other.ndim == 1:
result.grad_fn = DotBackward()
elif self.ndim == 1 or other.ndim == 1:
result.grad_fn = MvBackward()
else:
result.grad_fn = MmBackward()
return result在 Python 中,__matmul__这个 magic method 对应的运算符是矩阵乘法运算符 @,简单起见,限制了 other 的类型必须是 Tensor。
运算结果的 data 的计算,直接调用 numpy.ndarray 支持的 @运算(矩阵乘法)得到,但在后面指定 grad_fn 时,根据维度的不同进行了分类,即分为我前面给出的三种张量乘法类别。下面依次对这三种情况下的梯度反向传播函数进行分析。
DotBackward
此为两个一维向量的点积,由多变量微积分,容易得出以下结论:
对
class DotBackward(BackwardFcn):
def __init__(self):
super(DotBackward, self).__init__()
def calculate_grad(self, grad, children, place):
a = children[1 - place][0].data
return grad * a因为这是个二元运算,children 的下标 1-place 相当于取出两个运算数中的不同于当前位次的另一个,与前面梯度的表达式相一致。
MvBackward
此为一个张量与一个向量的乘积,在线性代数里,我们经常接触矩阵与向量的乘积,若张量维数超过了 2,即不再是矩阵时,其与向量的乘法应该怎样定义?
这里有一个与前面的广播机制类似的机制,对于一个维数超过 2 的张量,其与向量做乘法时,将视为多个形状相同的矩阵与向量分别做乘法。
上面说的不是很清楚,再举例解释一下:
我们知道
既然 Mv 乘法是这种类似于广播的机制,我们就可以同样按之前处理广播的手段来类似地处理梯度反传。
首先推导矩阵(二维张量)情况下的梯度反传公式(推导损失
第一种情形:
由多变量函数的链式法则易得:
第二种情形:
由多变量函数的链式法则易得:
虽然这两套公式本质上没区别,但我暂时没有找到把它们统一起来的优雅代码,因此我在反向传播的时候做了一个愚蠢的分类讨论,详细代码我就不贴了,请见我项目下 autograd/backward.py 中的 MvBackward 类。
关于广播的处理,因为这里只可能对向量进行广播,因此只需要在计算对向量的梯度时,进行一个求和操作即可。求和的维度根据张量
grad = np.sum(grad, tuple(range(a.ndim - 2))).reshape(x.shape)代码中的外积运算,并没有使用 numpy.outer,因为该函数只能用于两个一维的向量做外积,为了适应维度大于 1 的情形,需要将向量的外积运算通过扩展大小为 1 的维度,转化为标准的矩阵乘法运算。
MmBackward
此为两个维度大于 1 的张量的乘法运算,这种张量乘法对两个张量的形状有一定的要求,如下:
- 左张量的最后一个维度等于右张量的倒数第二个维度。(类似于矩阵乘法条件)
- 两个张量的形状去掉最后两个维度后,满足广播条件。
例如以下两个形状的张量积:
(2, 3, 4, 5) × (2, 3, 5, 6)=> (2, 3, 4, 6)
它的意义是,将第一个张量视为
与前面类似,这种情况下,我们先计算两个张量维度均为 2 的情形,再对需要广播的情况进行求和操作。若
则:
看上去居然比前面的 Mv 乘法形式还要简单。
这两个公式对应到代码中的形式如下:
# \frac{\partial L}{\partial A}
grad = np.matmul(grad, a.swapaxes(-1, -2))
# \frac{\partial L}{\partial B}
grad = np.matmul(a.swapaxes(-1, -2), grad)在多维情况下,使用 swapaxes 操作交换张量的最后两个轴,达到了公式里的转置效果。
然后再来解决广播情形,与前面类似,我们同样可以计算两个张量分别需要扩展的维度,区别在于,需要移除张量最后两个维度,因为这两个维度是用来做矩阵乘法的,不参与广播机制。详细代码请见 MmBackward 类。
本文涉及到的反传代码比较晦涩难懂,尤其是后面两个运算,涉及到 numpy 对维度的一些操作。另外,将矩阵乘法和梯度公式向高维推广的过程也很令人头大,需要各位仔细琢磨琢磨。
张量的乘法运算其实还包括两个一维向量的外积运算,不过我没有将这种乘法算在__matmul__方法中,而是单独实现了一个 outer 方法,向量外积运算的反向传播感觉比较容易,这里就略过了。
后面一篇文章,将举一些特殊的张量运算的例子。
- V me 50!
- Alipay is also ok~





















































































































































































































































































































































































































































.png)
.jpg)
.jpg)
.gif)
.jpg)
.gif)
.jpg)
.jpg)
.gif)
.jpg)
.gif)
.jpg)
.gif)
.jpg)
.png)
.jpg)
.jpg)
.gif)
.jpg)
.jpg)
.jpg)
.gif)
.gif)
.gif)
.jpg)
.gif)
.jpg)
.gif)
.jpg)
.gif)
.gif)
.gif)
.jpg)
.gif)
.jpg)
.gif)
.jpg)
.gif)
.jpg)
.jpg)
.gif)
.jpg)
.jpg)
.gif)
.gif)
.jpg)
.png)
.jpg)
.jpg)
.gif)